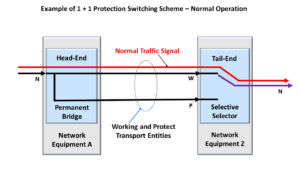
What is the 1:n Protection Switching Architecture?
ITU-T G.808 defines the “1:n (protection) architecture (n >= 1) as:
A 1:n protection architecture has n normal traffic signals, n working transport entities, and one protection transport entity.
It may have an extra traffic signal.
At the source end, a normal traffic signal is either permanently connected to its working transport entity and may be connected to the protection transport entity (in the case of a broadcast bridge) or is connected to either its working or protection transport entity (in the case of a selector bridge).
The sink-end can select the normal traffic signal from either the working or the protection transport entity.
An unprotected extra traffic signal can be transported via the protection transport entity whenever the protection transport entity is not used to carry a normal traffic signal.
What Does All This Mean?
As for all Protection Groups, a 1:n Protection Architecture consists of the following elements:
- n instances of the Head-End (or Source-End)
- n instances of the Tail-End (or Sink-End)
- and n separate Normal Traffic Signals
- n sets of Working Transport entities
- a single Protect Transport entity
- a single Extra Traffic Signal
- Protection Switching Controller (that can detect and declare defects within the Normal Traffic Signals).
- An APS Communications Link/Protocol (Required)
Figure 1 shows a variation of the 1:n Protection Switching architecture.
In this case, we show a 1:2 Protection Switching Architecture.
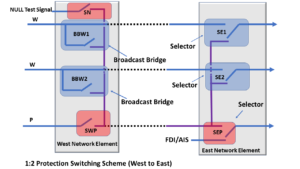
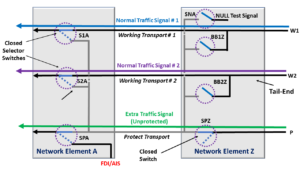
Figure 1, Illustration of a 1:2 Protection Switching Architecture
This figure shows that a Broadcast Bridge realizes each of the two Head-Ends (of this Protection Group). We realize each of the two Tail-ends by a Selector Switch.
I have designated the Broadcast Bridges with the Blue Overlay Shading in this figure.
Likewise, I have designated the Selector Switches with the Red Overlay shading.
NOTES:
- The user can also opt to realize the Head-ends with a Selector Switch for the 1:n Protection Switching Architecture.
- Figure 1 includes some other bells and whistles (in the form of some additional Selector Switches) that I will discuss later in this blog.
Clueless about OTN and Protection Switching? We Can Help!!! Click on the Banner Below to Learn More!!
Corporate Discounts Available!!!

How does the 1:n Protection Switching Architecture Work?
One of the noteworthy features of a 1:n Protection Switching Architecture is that you have a single Protection Transport entity that protects n Normal Traffic Signals.
This means that for the 1:n Protection Switching Architecture, you only need 1/n more bandwidth to transport the n Normal Traffic Signals in a protected manner, from the Head-ends to the Tail-ends (where n is the total number of Normal Traffic Signals that you are transporting via this Protection Group).
In contrast, for a 1+1 Protection Switching Architecture, you have one Protection Transport entity protecting one Normal Traffic Signal.
This means that we are providing the Normal Traffic Signal with twice the bandwidth required to transport this signal from the Head-End to the Tail-End in a protected manner.
For many applications, this is inefficient, expensive, and inconvenient.
Of course, this same ratio would also hold if you used a 1:1 Protection Switching Architecture.
Another Key Characteristic of a 1:N Protection Architecture
Another critical characteristic of a 1:N Protection Architecture is the use of Broadcast Bridges on the Head-End Circuitry. In contrast to a Permanent Bridge, during No-Defect Operation, there will not be a hardwired connection between the Normal Traffic Signal and the Working and Protection Transport entities. There is only the connection between the Normal Traffic Signal and the Working Transport Entity. When we are required to perform Protection-Switching, we will close the Broadcast Bridges and complete the electrical connection between the Normal Traffic Signal and the Protection Transport entity.
We will discuss how the 1:n Protection Switching Architecture works by examining the following cases/conditions.
- The Normal (No Defect) Case
- A service-affect defect occurring Working Transport entity # 1
- Protection Switching (after the defect has been declared).
- The Normal (No Defect) Case – also using the Extra Traffic Signal
The Normal (No Defect) Case
Figure 2 shows a drawing of the Normal (No Defect) Case.
In this case, we have two Network Elements that are exchanging data with each other.
One Network Element (which we labeled Network Element West) is transmitting data to another Network Element (which we labeled Network Element East).
In most actual applications, we would also have traffic going in the opposite direction (East to West).
But, to keep these figures simple, we are only showing one direction of traffic in each of the figures in this post.
In Figure 2, Normal Traffic Signal # 1 travels over Working Transport entity # 1.
Likewise, Normal Traffic Signal # 2 travels over Working Transport entity # 2.
Additionally, the Extra Traffic Signal is traveling over the Protection Transport entity.
There are no impairments on any of the Working Transport entities, and everything is expected in this case.
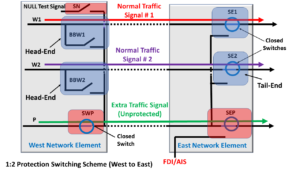
Figure 2, Illustration of the Normal (No Defect) Case
A Service-Affecting Defect occurs in Working Transport entity # 1
Now, let us assume that an impairment occurs in Working Transport entity # 1, such that some circuitry (sitting within the Tail-End of this Working Transport entity, within Network Element East) is declaring either a service-affecting defect such as SF (Signal Fail) or the signal degrade defect, such as SD (Signal Degrade).
In this case, Normal Traffic Signal # 1 can no longer travel on the Working Transport entity # 1.
Figure 3 shows a drawing of this condition.
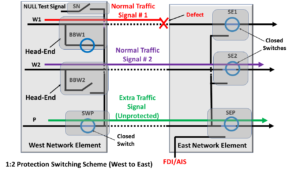
Figure 3, Illustration of a Service-Affecting Defect Occurring in Working Transport Entity # 1
Protection Switching – After the Defect (in Working Transport Entity # 1) has been declared
Now, since the Tail-End circuitry of Working Transport entity # 1, within Network Element East) has declared this defect condition, it needs to invoke Protection Switching.
In particular, this circuitry needs to perform the following four tasks.
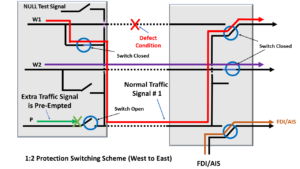
- The circuitry within Network Element East needs to switch the local Selector Switch, which I’ve labeled SE1 (at the Tail-End of Working Transport entity # 1), away from this (now failed) Working Transport entity over to selecting the Protection Transport entity.
- The Network Element East circuitry also needs to send a command across the Transport entities back to the upstream Network Element (e.g., Network Element West). In this case, Network Element East will also command Network Element West to invoke Protection Switching (for Working Transport entity # 1).
- Next, Network Element West (after it has received this command from Network Element East) then needs to command the Broadcast Switch, which I’ve labeled BBW1 (at the Head-end of Working Transport Entity # 1) to switch such that Normal Traffic Signal # 1 is now also connected to the Protection Transport entity.
- Finally, Network Element West needs to pre-empt the Extra Traffic signal by opening the switch that I’ve labeled SWP. Once this switch is OPEN, the Extra Traffic signal will no longer travel across the Protection Transport entity.
In this case, Normal Traffic Signal # 1 will now travel (from Network Element West to Network Element East) using the Protect Transport entity.
Figure 4 presents the resulting configuration (with Network Elements East and West) after protection switching.
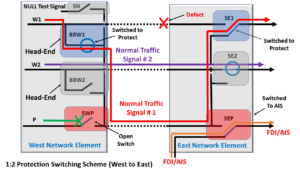 Figure 4, Illustration of our 1:2 Protection Switching Protect Group, following Protection Switching
Figure 4, Illustration of our 1:2 Protection Switching Protect Group, following Protection Switching
NOTE: Protection Groups using the 1:n Protection Switching scheme are required to support an APS Communications Channel to command and coordinate Protection Switching activities between the Head-ends and Tail-ends of the Protection Group.
This is how 1:N Protection Switching works.
Has Inflation got You Down? Our Price Discounts Can Help You Beat Inflation and Help You Become an Expert on OTN and Protection Switching!!! Click on the Banner to Learn More!!
Discounts Available for a Short Time!!
Additional Options in the 1:n Protection Switching Architecture
There are several options that users can use when designing a 1:n protection switching scheme.
Some of these options include:
- Transmitting the NULL Signal during the Normal (No Defect) Case – as the Extra Traffic signal.
- Transmitting the FDI/AIS signal during Protection Switching
- Revertive Protection Switching
- Unidirectional or Bidirectional protection switching
We will briefly discuss each of these options below.
Transmitting the NULL Signal during the Normal (No Defect) Case – as the Extra Traffic Signal.
In some cases, the user can transmit the NULL signal as the Extra Traffic signal (via the Protect Transport entities) anytime each of the n Working Transport entities is defect-free and is functioning properly.
In the Protection Group (discussed in this post), we could close the Switch labeled SN and open the Switch labeled SWP (within Network Element West).
This configuration setting would allow the NULL signal (that originates from Network Element West) to flow through the Protect Transport entity, as shown in Figure 5.
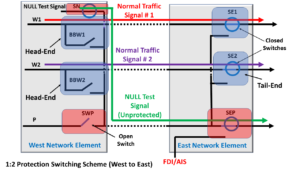
Figure 5, Transmitting the NULL Signal via the Protect Transport Entity, during Standby Times.
Transmitting the FDI/AIS signal during Protection Switching
In many cases, the user will transmit the FDI/AIS signal towards the circuitry downstream from Network Element East by switching the switch, which I’ve labeled SEP (within Network Element East), away from the Protect Transport entity towards the FDI/AIS signal source.
Figure 4 (above) shows Network Element East transmitting the FDI/AIS indicator towards downstream traffic during Protection Switching.
The user would typically only do this whenever the Extra Traffic Signal (e.g., the NULL signal or some other low-priority signal) has been pre-empted due to a Protection Switching event.
The purpose of transmitting this FDI/AIS signal is to alert downstream equipment of a service-affecting defect condition within one of the Working Transport entities between Network Elements East and West.
NOTE: For OTN applications, the Network Element will transmit the ODUk-AIS indicator during these protection switching events.
Revertive Protection Switching
Some Protection Groups will support Revertive operations, and others will not.
Suppose you designed a Protection Group to support Revertive operations. In that case, the Protection Group will automatically reroute the affected Normal Traffic Signal back through its Working Transport entity shortly after the servicing-affecting defect (which caused the protection switching event in the first place) has cleared.
1:n Protection Switching systems typically support Revertive operations, whereas 1+1 Protection Switching systems may NOT support Revertive operations.
If a 1:n Protection Switching system was to support Revertive operations, then the Network Element that first declared (and is now clearing) the service-affecting defect; would have to send a command back to the other (remote) Network Element to coordinate revert protection switching activities (between both the Head-Ends and Tail-Ends of the Protection Group).
Please see the post on the Revertive Operation and the Automatic Protection Switching Channel for more details on this topic.
Unidirectional or Bidirectional Protection Switching
A 1:n Protection Switching scheme can support either Unidirectional or Bidirectional Protection Switching.
If the Protection Group supports Unidirectional Protection Switching, then the Network Element (that detects and declares the Service-Affecting defect within one of the Working Transport entities) will need to send the necessary command information (back to the upstream Network Element) to command and coordinate the Unidirectional Protection Switching event.
Conversely, suppose the Protection Group supports Bidirectional Protection Switching. In that case, the Network Element (that detects and declares the Service-Affecting defect) will need to send the necessary command information (back to the upstream Network Element) to command and coordinate the Bidirectional Protection Switch.
Please see the posts for Unidirectional and Bidirectional Protection Switching for more details on this topic.
Has Inflation got You Down? Our Price Discounts Can Help You Beat Inflation and Help You Become an Expert on OTN!! Click on the Banner Below to Learn More!!!
Discounts Available for a Short Time!!
Click on the Image Below to see more Protection-Switching related content on this Blog:

Protection-Switching Related Blog Posts Basic Protection-Switching Terms Head-End (Source Node) Hold-Off Timer Protection-Group Protection-Transport entity Selector Switch Tail-End (Sink Node) ...