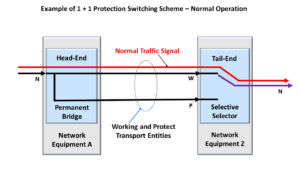
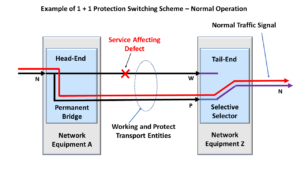
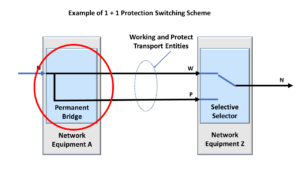
What is Shared-Ring Protection Switching?
A Shared-Ring Protection Switching system is a Protection System that contains at least three (3) Nodes.
Each Node within this Shared-Ring Protection-Switching System (or Ring) is connected to two neighboring nodes.
I show an illustration of a Shared-Ring Protection-Switching System below in Figure 1.
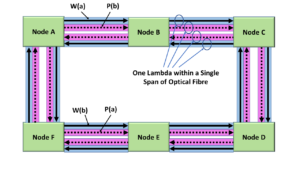
Figure 1, Illustration of a Shared-Ring Protection-Switching System
Figure 1 presents a shared-ring protection-switching system that consists of six (6) nodes that are each connected to a shared ring that contains four (4) Optical loops (or rings).
Some optical rings carry traffic that flows in the clockwise direction (through each node). Other rings carry traffic that flows in the counter-clockwise direction.
In Figure 1, I have labeled some of these optical loops as “Working” or Working Transport Entity loops and others as “Protect” or Protection Transport Entity loops.
What are the Nodes within a Shared-Ring Protection-Switching System?
Each node (on the Shared-Ring Protection-Switching system) is an electrical/optical system that functions similarly to an Add-Drop-MUX.
Some data traveling on an optical loop (within the ring) will pass through these nodes. These Nodes also can add in and drop-out some of the data traveling on these loops.
I show the Add-, Drop- and Pass-Through capability of these Nodes below in Figure 2.

Figure 2, Illustration of the Add-, Drop- and Pass-Through capabilities of a given node, sitting on the shared-ring.
It is also important to note that each Node can function as either a Source (or Head-End) Node, a Sink (or Tail-End) Node, or both.
Types of Shared-Ring Protection-Switching Systems
ITU-T G.873.2 defines the following two types of Shared-Ring Protection-Switching systems.
- The 2-Fibre/2-Lambda Shared-Ring Protection-Switching system, and
- The 4-Fibre/4-Lambda Shared-Ring Protection-Switching system.
Please click on the links above to learn more about these Shared-Ring Protection-Switching systems.
Types of Protection-Switching within a Shared-Ring Protection-Switching System
The Shared-Ring Protection-Switching system can support both the following kinds of Protection-Switching.
- Span-Switching (not available within the 2-Fibre/2-Lambda Shared-Ring Protection-Switching system)
- Ring-Switching
Click on the above links to learn more about these types of Protection-Switching within a Shared-Ring Protection-Switching system.
Design Variations for Shared-Ring Protection-Switching Systems
Shared-Ring Protection-Switching systems are available in a wide variety of features. I’ve listed some of these features and their possible variations below.
Shared-Ring Protection-Switching Types
- 2-Fibre/2-Lambda Shared-Ring Protection-Switching systems
- 4-Fibre/4-Lambda Shared-Ring Protection-Switching systems.
Architecture Type
All Shared-Ring Protection-Switching is of the 1:N Protection-Switching Architecture.
Switching Type
All Shared-Ring Protection-Switching is Bidirectional.
Operation Type
All Shared-Ring Protection-Switching systems use Revertive Operation.
APS Protocol – Using the APS/PCC Channel
All Shared-Ring Protection-Switching systems use the APS Protocol.
What about other types of Protection-Switching?
Other types of Protection-Switching Systems are not Shared-Ring, such as Linear or Shared-Mesh Protection-Switching.
Has Inflation got You Down? Our Price Discounts Can Help You Beat Inflation and Become an Expert on OTN!! Click on the Banner Below to Learn More!!
Discounts Available for a Short Time!!!

Please Click on the Image below to See More Protection-Switching posts within this Blog.