What is the NULL Test Signal for OTN?
What Exactly is the NULL Test Signal for OTN?
The NULL signal (for OTN) is an OPUk frame with all the following characteristics.
- The PT (Payload Type) byte-field (within the PSI) is set to the value 0xFD (which indicates that this OPUk frame is transporting the NULL signal).
- The rest of the 7 RES (Reserved) byte-fields (within the OPUk Overhead) are all set to an All-Zeros pattern (0x00).
- All the payload bytes (within the OPUk frame) are set in an All-Zeros pattern.
Figure 1 shows a drawing of an OPUk Frame transporting the NULL signal.
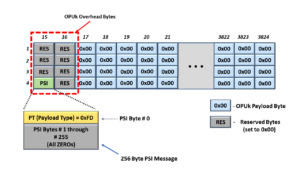
Figure 1, An Illustration of the OPUk frame that is transporting the NULL signal
Any ODUk or OTUk frame that transports an OPUk frame with these characteristics carries the NULL signal.
Additionally, any of the following types of OPUk/ODUk signals can transport the NULL signal:
- OPU0/ODU0
- OPU1/ODU1
- OPU2/ODU2
- OPU2e/ODU2e
- OPU3/ODU3
- OPU4/ODU4
- OPUflex/ODUflex
Clueless about OTN? We Can Help!! Click on the Banner Below to Learn More!!
Corporate Discounts Available!!!

Where and How would one use the NULL Signal?
ITU-T G.709 defines the NULL signal (for OTN) as a test signal.
Therefore, the System Architect can consider the NULL signal as a tool (in the toolbox) for testing and debugging features available to an OTN system.
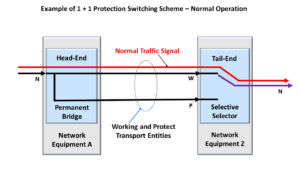
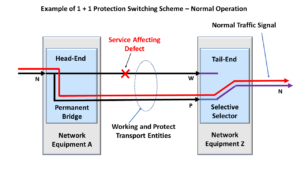
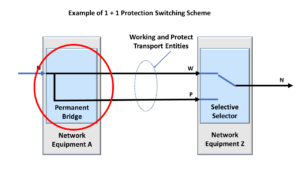
Some system applications will transmit the NULL signal via the Protection Transport entity within a 1:1 or 1:n protection switching scheme. In this case, the user will send the NULL signal instead of either the Extra-Traffic Signal or the ODUk-OCI Maintenance Signal.
Figure 2 shows a drawing of the 1:2 Protection Switching scheme, in which the user is transporting the NULL signal via the Protection Transport Entity.

Figure 2, An Illustration of a 1:2 Protection Switching scheme that is transporting the NULL signal via the Protection Transport entity
We can use the NULL signal in any application or situation whenever we need to continuously supply an optical signal (that is carrying timing information) to keep Clock Recovery PLL circuitry (within a downstream Network Element) locked onto the timing signal in the local Network Element.
Simultaneously, the NULL signal will indicate to the downstream Network Element that the connection is working correctly and that there are no defects upstream.
The NULL signal is unlike an AIS signal, which does indicate (to downstream Network Elements) the presence of service-affecting defect conditions upstream.
How Should a System Designer create the NULL Signal for OTN Applications?
The NULL signal (for OTN applications) consists of a fixed pattern.
Therefore, the user can generate OPUk signals (transporting the NULL signal) using a Pattern Generator, which gets its timing from a local clock oscillator.
The System Designer must also ensure that this NULL Signal generator function generates both the OTUk/ODUk Frame and Multi-Frame start indicators.
The Frame Start indicator (FS) should occur every 122,368 clock cycles (or ODUk frame period).
And the Multi-Frame Start indicator (MFS) should occur every 256 frames.
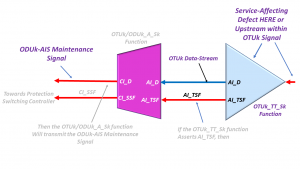
ITU-T G.798 specifies an adaptation function of the name ODUkP/NULL_A_So.
This function is responsible for generating an ODUk signal transporting the NULL signal.
This adaptation function generates the NULL signal from a free-running clock source, which then maps this signal into an OPUk/ODUk frame.
Finally, this function includes the OPUk overhead (e.g., the RES and PT fields) and a default ODUk overhead.
NOTE: In the case of the default ODUk overhead, this function will set all the ODUk overhead fields to All-Zeros, except for the PM STAT field, which will be set to the value 001 (to indicate a Normal Path Signal).
Figure 3 illustrates the ODUkP/NULL_A_So function from ITU-T G.798.

Figure 3 illustrates the ODUk/NULL_A_So function from ITU-T G.798.
What are the Timing (Frequency Accuracy), Jitter, and Wander Requirements for the NULL Signal?
Please see the ODCa (ODU Clock for Asynchronous Mapping) post for the complete Frequency Accuracy and Jitter/Wander requirements of this NULL signal.
Summary
The NULL signal, for OTN applications, is an OPUk frame that has ALL the following characteristics:
- All the Payload bytes have the value 0x00 (All Zeros).
- The PT (Payload Type) byte (within the PSI message) has the value of 0xFD (which identifies this particular signal as being the NULL signal)
- All remaining OPUk overhead fields will be of the value of 0x00 (All Zeros).
Additionally, within the ODUk overhead, the PM STAT field should be set to the value 001.
The NULL signal is a test signal that one can use for test and debugging purposes.
The System Design can also use the NULL signal as a replacement signal for a signal that is unavailable due to user configuration reasons.
Has Inflation got You Down? Our Price Discounts Can Help You Beat Inflation and Help You Become an Expert on OTN!! Click on the Banner Below to Learn More!!
Discounts Available for a Short Time!!
For More Information on OTN Posts in this Blog, click on the Image below.